 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[多选题]
()關於資料集的類比描述何者正確
A.驗證集像是一場模擬考
B.訓練集就像是深度學習模型的教科書
C.測試集對於模型來說則是最終決定成果的考試
D.驗證集對於模型來說則是最終決定成果的考試
E.測試集像是一場模擬考
 如搜索结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如搜索结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.驗證集像是一場模擬考
B.訓練集就像是深度學習模型的教科書
C.測試集對於模型來說則是最終決定成果的考試
D.驗證集對於模型來說則是最終決定成果的考試
E.測試集像是一場模擬考
如搜索结果不匹配,请 联系老师 获取答案
 更多“()關於資料集的類比描述何者正確”相关的问题
更多“()關於資料集的類比描述何者正確”相关的问题
第1题
A.正交集 (orthogonal set)
B.訓練集(training set)
C.驗證集(validation set)
D.平行集(parallel set)
E.測試集(testing set)
第5题
A.聚類(clustering)是一種非監督式學習
B.聚類(clustering)是一種監督式學習
C.使用的資料不需要包含類別標籤
D.使用的資料需要包含類別標籤
E.常見的基本聚類方法有 K- 平均演算法和階層式聚類
第6题
A.是訓練過程中用來度量分類器輸出錯誤程度的數學化表示
B.預測錯誤程度越大,損失函數的取值就越大
C.定義合適的損失函數對於訓練分類器是非常重要的
D.損失函數是在整個訓練集上求得的,如果用它來更新參數,則是利用了整個數據集中被誤分類的數據
E.感知器和支持向量機是基於相同的損失函數建立起來的
第7题
A.是一種訓練分類器的算法
B.利用被誤分類的數據調整現有分類器的參數,使調整後的分類器判斷更加準確
C.感知器的學習算法就是不斷減少對數據誤分類的過程
D.感知器的損失函數是在整個訓練數據集上求得的
E.以上皆是
第8题
A.分群問題被定義為:將未知的新訊息歸納進已知的資訊中
B.機器學習領域中的分群問題,重點在於新的資料和已分類的資料互相比較,看看新資料在分類過的資料中,和哪一類資料比較類似
C.分類問題就是一群資料中沒有明確的分類或群體,而是必須透過它們所具有的特徵做區分
D.分群的問題要事先幫資料做標籤 (label)
E.分群的基礎在於要根據可以區分出兩種群體的特徵來分群
第9题
A.分類的演算法都稱為監督式學習
B.分類的演算法都稱為非監督式學習
C.分群的演算法都稱為監督式學習
D.分群的演算法都稱為非監督式學習
E.決策樹(decision tree)是機器學習分類的技術
第10题
A.Google AlphaGo也是奠基於機器學習,透過電腦運算對手下棋的頻率
B.廣泛應用在圖像、影像識別、推薦系統、輔助決策等金融、醫療、國防民生領域
C.深度學習網路就像黑盒子 (black box),人們不容易理解模型中各網路層的內涵,就無法做出有效的調整
D.透過 CNN 模型,你可以輸入一張圖片,得到該圖片屬於哪種類別的結果,這過程我們把他稱作分類 (Classification)
E.行為理解問題一般遵從如下基本過程:特徵提取與運動表徵、行為識別、高層行為與場景理解
第11题
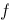 何者正確?如果
何者正確?如果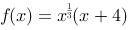 。
。A.Increasing on (0 , ∞)
B.Increasing on (-4 , ∞)
C.decreasing on (-∞ , -4)
D.decreasing on (-4 , -1)




为了保护您的账号安全,请在“上学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

 微信搜一搜
微信搜一搜
 上学吧
微信搜一搜
上学吧
上学吧
微信搜一搜
上学吧















