 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
关于聚类分析的说法,不正确的是_________。
A.聚类是无监督学习方法
B.聚类可作为分类等其他任务的预处理过程
C.聚类分析目标是使同一个簇中的样本相似度较高,而不同簇间的样本相似度较低
D.“簇”越多说明聚类效果越好
 如搜索结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如搜索结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.聚类是无监督学习方法
B.聚类可作为分类等其他任务的预处理过程
C.聚类分析目标是使同一个簇中的样本相似度较高,而不同簇间的样本相似度较低
D.“簇”越多说明聚类效果越好
如搜索结果不匹配,请 联系老师 获取答案
 更多“关于聚类分析的说法,不正确的是_________。”相关的问题
更多“关于聚类分析的说法,不正确的是_________。”相关的问题
第1题
A、聚类分析可以分为样品分类和指标分类
B、聚类的依据是相似性统计量
C、Proc cluster是sas进行聚类分析的命令程序
D、相似性统计量有相关系数和距离两种
第2题
A、聚类模型属于无监督学习
B、聚类模型的本质是寻找数据集内在的分布结构
C、经过聚类之后的数据集形成不同的簇,同簇的样本相似度低,簇间的样本相似度高
D、聚类模型作为独立的分析过程,通常不和其他数据分析任务结合叠加
第4题
A、对于基于密度的聚类而言,不是根据样本的距离,而是根据样本的密度进行分组的。
B、在基于密度的聚类中,样本的邻域距离阈值参数不同,可能得到不同的聚类结果。
C、在聚类过程中,非数值型属性必须转为数值属性才能进行聚类分析。
D、在使用kmeans聚类时,k值总是很容易给出。
第6题
A、pandas没有做哑变量的函数
B、在不导入其他库的情况下,仅仅使用pandas就可实现聚类分析离散化
C、pandas可以实现所有的数据预处理操作
D、cut函数默认情况下做的是等宽法离散化
第7题
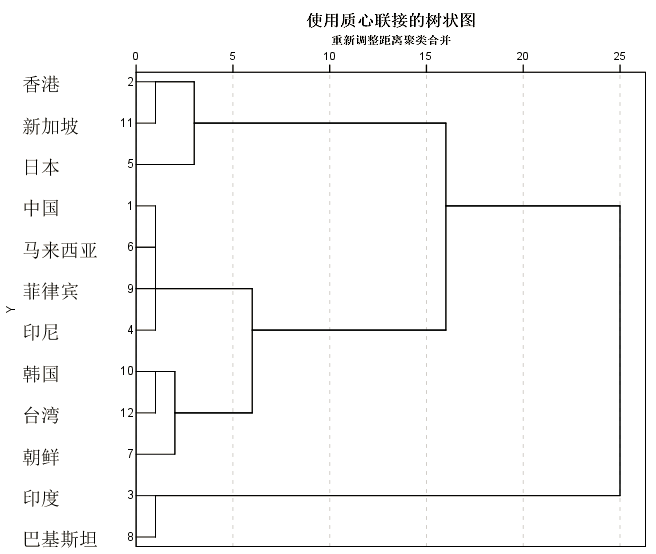 以下说法不正确的是:
以下说法不正确的是:A、分为四类时,印度和巴基斯坦构成一个类
B、分为四类时,日本、中国、马来西亚构成一个类
C、分为两类时,日本、香港、新加坡在同一个类内
D、分为三类时,日本、香港、新加坡在同一个类内
第8题
以下说法不正确的是:A、分为四类时,印度和巴基斯坦构成一个类
B、分为四类时,日本、中国、马来西亚构成一个类
C、分为两类时,日本、香港、新加坡在同一个类内
D、分为三类时,日本、香港、新加坡在同一个类内
第9题
1.一个机器学习模型,如果有较高准确率,总是说明这个分类器是好的
2.如果增加模型复杂度,那么模型的测试错误率总是会降低
3.如果增加模型复杂度,那么模型的训练错误率总是会降低
4.我们不可以使用聚类“类别id”作为一个新的特征项,然后再用监督学习分别进行学习
A.1
B.2
C.3
D.1and3




为了保护您的账号安全,请在“上学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

 微信搜一搜
微信搜一搜
 上学吧
微信搜一搜
上学吧
上学吧
微信搜一搜
上学吧















