 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
关于文档的向量表示模型,采用深度学习中的词向量表示模型和传统的单纯基于词频向量表示方法的区别的描述错误的是
A.传统文档的表示一般采用词袋BOW模型,表示为高维向量
B.深度学习中的词向量表示模型通常是一种低维度向量
C.深度学习中的词向量表示模型存在的一个突出问题就是“词汇鸿沟”现象
D.传统方法中词向量表示模型存在一个突出问题就是“词汇鸿沟”现象
 如搜索结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如搜索结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.传统文档的表示一般采用词袋BOW模型,表示为高维向量
B.深度学习中的词向量表示模型通常是一种低维度向量
C.深度学习中的词向量表示模型存在的一个突出问题就是“词汇鸿沟”现象
D.传统方法中词向量表示模型存在一个突出问题就是“词汇鸿沟”现象
如搜索结果不匹配,请 联系老师 获取答案
 更多“关于文档的向量表示模型,采用深度学习中的词向量表示模型和传统…”相关的问题
更多“关于文档的向量表示模型,采用深度学习中的词向量表示模型和传统…”相关的问题
第1题
A、IBM的统计机器翻译模型除了通过统计方法,还需要借助语言知识和一些转换规则
B、基于规则的机器翻译方法无法用有限的规则覆盖所有复杂的语言现象
C、IBM的Brown等人提出的“基于词对齐的统计机器学习翻译模型”标记着现代统计机器翻译方法的诞生
D、Mikolav等人开源的Word2Vec工具将词表示为一系列实数组成的词向量,从而将语言智能问题转变为神经网络计算问题
第2题
A、由斯坦福大学研发
B、将词表示为低维实数值向量的工具
C、和word2vec类似,也可以作为深度学习中预初始化的词向量
D、其它答案都不对
第3题
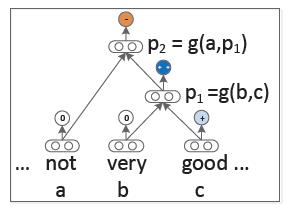
A、每个词通常初始化表示为一个d维的向量。由一个随机均匀分布随机采样生成
B、所有的词向量被存储在一个词嵌入矩阵中。随着训练的进行,该矩阵将被视为一种参数,因此会被学习调整
C、不同长度和句法类型的句子其组合词向量的维度都不同
D、树结构基于句法分析器生成
第5题
A.基于经验的过程
B.学习可以看作是一个暂时的行为或心理的变化的过程
C.学习是行为的相对一致的变化
D.学习是行为或行为潜能的变化
第6题
A、基于特征人脸的人脸识别
B、Word2Vec词向量生成
C、Alpha Go
D、基于卷积神经网络的手写体图像识别
第7题
A、“课程”一词含有学习的范围和进程的意思
B、课程就是教材
C、课程随社会的发展而演变,反映一定社会的政治、经济要求
D、狭义的课程是指一门学科,如数学课程、语文课程
第9题
B、机器学习的四个步骤中,文档特征抽取是指利用抽取算法抽取查询词TF/IDF信息、文档长度、网页PageRank值、网页入链/出链数量等
C、中文分词技术采用了基于符号的方法来识别
D、动态索引包含2个关键的索引结构:倒排索引、临时索引




为了保护您的账号安全,请在“上学吧”公众号进行验证,点击“官网服务”-“账号验证”后输入验证码“”完成验证,验证成功后方可继续查看答案!

 微信搜一搜
微信搜一搜
 上学吧
微信搜一搜
上学吧
上学吧
微信搜一搜
上学吧















