 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
PageRank算法是基于网页链接分析对关键字匹配搜索结果进行处理的。它借鉴传统引文分析思想:当
网页甲有一个链接指向网页乙,就认为乙获得了甲对它贡献的分值,该值的多少取决于网页甲本身的重要程度,即网页甲的重要性越大,网页乙获得的贡献值就越高。由于网络中网页链接的相互指向,该分值的计算为一个迭代过程,最终网页根据所得分值进行检索排序。
互联网是一张有向图,每一个网页是图的一个顶点,网页间的每一个超链接是图的一个边,邻接矩阵B=(b)w如果从网页i到网页j有超链接,则by=1,否则为0。
记矩阵B的列和及行和分别是 它们分别给出了页面j的链人链接数目和页面i的链出链接数目。假如在上网时浏览页面并选择下一个页面的过程,与过去浏览过哪些页面无关,而仅依赖于当前所在的页面。那么这一-选择过程可以认为是一一个有限状态、离散时间的随机过程,其状态转移规律用Markov链描述。定义矩阵A=(ay)wxn为
它们分别给出了页面j的链人链接数目和页面i的链出链接数目。假如在上网时浏览页面并选择下一个页面的过程,与过去浏览过哪些页面无关,而仅依赖于当前所在的页面。那么这一-选择过程可以认为是一一个有限状态、离散时间的随机过程,其状态转移规律用Markov链描述。定义矩阵A=(ay)wxn为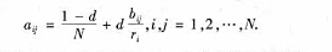 式中:d是模型参数,通常取d=0.85;A是Markov链的转移概率矩阵;ay表示从页面i转移到页而j的概率。根据Markov链的基本性质,对于正则Markov链存在平稳分布x=
式中:d是模型参数,通常取d=0.85;A是Markov链的转移概率矩阵;ay表示从页面i转移到页而j的概率。根据Markov链的基本性质,对于正则Markov链存在平稳分布x= 式中:x为在极限状态(转移次数趋于无限)下各网页被访问的概率分布,Google将它定义为各网页的PageRank值。假设x已经得到,则它按分量满足方程
式中:x为在极限状态(转移次数趋于无限)下各网页被访问的概率分布,Google将它定义为各网页的PageRank值。假设x已经得到,则它按分量满足方程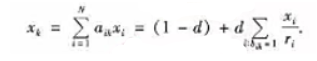 网页i的PageRank值是划,它链出的页面有τ个,于是页面i将它的PageRank值分成r份,分别“投票"给它链出的网页。x为网页k的PageRank值,即网络上所有页面“投票给网页k的最终值。根据Markov链的基本性质还可以得到,平稳分布(即PageRank值)是转移概率矩阵A的转置矩阵AT的最大特征值(=1)所对应的归一化特征向量。
网页i的PageRank值是划,它链出的页面有τ个,于是页面i将它的PageRank值分成r份,分别“投票"给它链出的网页。x为网页k的PageRank值,即网络上所有页面“投票给网页k的最终值。根据Markov链的基本性质还可以得到,平稳分布(即PageRank值)是转移概率矩阵A的转置矩阵AT的最大特征值(=1)所对应的归一化特征向量。
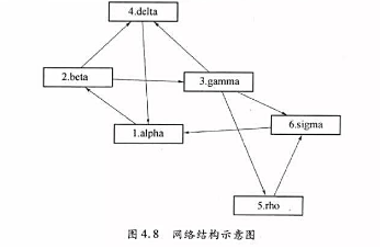
已知一个N=6的网络如图4.8所示,求它的PageRank取值。
 如搜索结果不匹配,请 联系老师 获取答案
如搜索结果不匹配,请 联系老师 获取答案























